
编程,说白了就是人类和计算机内存打交道的东西。
也就是人类的东西如何存进计算机,然后利用计算机的计算,得出的结果就是人类要用的。
那如何将键盘的东西存进内存?又如何取出?

如果你理解了这一点,那么你也就懂了差不多50%,剩下的50%就是你的大脑逻辑了-也就是如何让运算更有逻辑,更有想法。
如果想一天就懂编程的50%知识,那我就大概说一下:
编译器与标准

你们听错,很多人一来就是一句
hello world
但你们谁知道,hello world是怎么出现在屏幕的?
靠的还是
编译器与标准
编译器
就是我们人类用我们人类懂得的高级语言,经过编译器的处理存入内存里。比如转二进制、转十六进制等等。把它们都缩小在缩小的存入内存里,相当于把东西放入仓库集合。
而编译器,又是根据什么来处理?
标准
所谓的标准是个概念词,标准它很大也很杂。比如:计算机里的函数集lib(library)、个人开发的函数库集(lib)、国家级的函数集标准(lib)、世界级的函数集(lib)等,这些都是认为已经开发好的函数集,统称为开发好的标准。所以标准,只是一个函数集里的一些函数运行逻辑,它让编译器按这个函数集里的逻辑来进行人类语言与机器语言的处理。
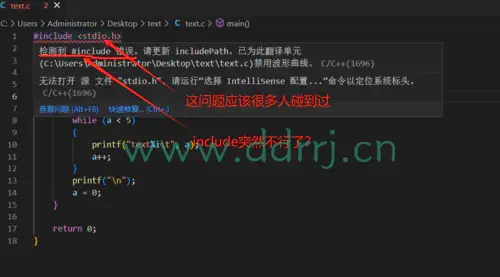
所以就有#include <>这个外调命令。
如果没有#include<>这个外调命令,你在编译器不过怎么输入逻辑代码,编译器不知道怎么处理这些人类语言代码去与机器沟通。
像我们每次编程时,都要#include <stdio.h>里的stdio.h文件,这个就是个函数库,你可以看看你编译器的存放路径,找到include文件夹就能看到。
而有的标准,是我们买电脑后,它就已经在电脑里了,例如lib库和dll库。
如果电脑里没有这些标准文件,电脑根本运行不了,因为没有标准指令,系统不知道怎么运行。
有的游戏会要求你下载dll库函数文件,那是因为找不到你电脑里有这些东西,就会让你去下载这些标准指令,游戏才知道怎么配合电脑处理运行。
后面学到函数,你们也就懂了。我们自己都可以做自己的函数标准,让编译器按我们的标准来进行与机器的沟通。

我们这就来说说:
数字1、2、3、4、5等等数字,是如何存入内存的?
+-*/等其它符号和英文字母是怎么存入内存的?
汉字以及不属于英文字母的语言是怎么存入内存的?
戴戴答:全部转为二进制!!!
因为计算机只认识二进制:01010101这种的。
而编译器调用的stdio.h文件的标准,就已经让编译器怎么转为进制格式存入内存里了。
也就是所谓的格式化输入i,格式化输出o
读书都学过二进制吧?逢二进一。跟我们平常用的十进制不同,十进制是从0-10,其实是11位,但认为0是没有的数字,所以很多都是1-10,逢十进一。
但计算机很讲究0,0在计算机内存里也占用一个位。
位
在计算机里,位又是什么?
有研究电脑的,都知道电脑里有个32位电脑、64位电脑,这个又是什么意思?
计算机里的内存都有位,一个位为1bit,属于内存最小单位。
我们说过了,计算机内存只放二进制,也就是1个位里只放0或1。
而在计算机内存里,0和1其实不能说是数字,它更像是一个开关。
1代表这个内存位打开了,0代表这个内存位为关闭。

我这里引入一个故事:很久很久以前……

其实不是故事,是历史啦。
在第一台计算机出现时,人们将英文字母转为二进制放入计算机内存里时,都是通过这样:

你没看错,这就只是台计算机,而不是我们现在的机房。
每一个插孔就是一个开关。有插线就代表内存里的位是1打开,没插线的就是0关闭。
所以说白了,就是个开关。
旁白:你丫的说了半天,到底在说什么。
别急别急,现在已经明白位里面的0代表关,位里面的1代表开。那我们就继续讲位。
在内存里,一个位里可以放一个1或是一个0,那么八个位就是
0000 0000
或是
1111 1111
又或是
0101 1010
等等,这八个位的开关不管怎么变,都局限在这8个位里,我们就叫字节;
1个字节=8个位,8个位=1个字节;

然后我们再看看,我们从键盘,通过编译器按了一个数字1,这个数字1通过编译器翻译成二进制就是
0000 0001

说1,你们看不出来了,那我们键盘在打三个数字,就打 99
99 通过编译器编程成二进制,是怎么进入内存的呢?
我们继续列8个位出来:
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
不知道这么说是否明白?

对应的开关数字呢,就是从最右边的0开始,如果有8位内存,每一个开关位的下面都是一个2次幂计算得出。
记住:
右边第一个开关位要么是0关,要么是1打开也是数字1。
而从右边开始第二位,0关闭就不算,1打开对应的就是数字2。
右边起第三位,0关闭不算,1打开对应的就是数字4。
依次类推,进行而次幂的运算过去。
说到这里,那数字99怎么换算二进制进入内存?
我们在看看这个对应表:
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
99=多少相加?计算机内存会通过≤99的最靠近数字打开位二进制1,依此往下相加,直至得出是99后就打开与其匹配得出99的那个位为1。
那我们得出小于或等于99最靠近的数字是多少?64。
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
64+32=96 对上了吗?对上了,那就匹配的32这个数字的开关打开
| 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
96+16=102,这个不匹配吧?不匹配,那这个位还是0关闭。
然后继续96+8=104,也不是,这个位也是0关。
96+4=100,也不是,也是0关。
96+2=98,这次匹配了,这个位开为1.
| 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 |
| 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
98+1=99?对了,这个位也打开为1.现在已经满足数字99了,
| 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 |
| 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
01100011
你们手机或电脑搜索二进制转换,把二进制这个数字转为十进制,是不是数字是99,或者把十进制数字99转为二进制,是不是:01100011。
这就是数字如何存入内存里,又如何从内存里取出来的过程

好了,那电脑32位和64位是什么意思呢?
这个其实应该不是只叫位,因为电脑很讲究地址寻址这个东西,后面学到指针你们就懂了,现在说,你们可能还不懂。
那32位地址电脑我们把1全部打开
就是32个开关全打开为1:
11111111111111111111111111111111
我们刚才已知打开的开关底下都有一个对应的数字,对应的数字依次从右到左而次幂计算。那2的32次幂是多少?
对应的所有数字相加,就是32位的数值!!!等于数字:
4294967296bit

而且不止哦,这个还算少了,我这个只是地址开关的位(这个地址后面会说,你们看看就好。)每个地址还指向了1个字节哦,因为每个地址指向一个字节的原因是计算机内存是按字节寻址的,即内存的最小单元是一个字节。1个字节是8位,也就是还要乘8哦,最终数字应该是:
34359738368 bit
懂电脑的应该还懂得,位的叫法是:bit
1GB内存=1024MB,1MB=1024KB,1KB=1024B,1B=8bit.
我们开始计算:
34359738368/8=4294967296 B 叫字节
4294967296/1024=4194304 KB 叫千字节
4194304/1024=4096 MB 兆字节
4096/1024=4 GB 吉字节
32位电脑,就是4GB内存电脑。你的电脑处理能力可以处理4G的东西,满足普通个人,如果要处理更大的东西,比如绘图程序或大型开放世界单机游戏啥的,一次要加载超过4G以上的模型、地图啥的数据东西,你的32位电脑就真处理不过来,导致卡顿,卡死,爆内存,蓝屏,关机等。所以
64位电脑,更适合处理大型的数据,当然,这个只是一个处理问题,如果要处理一些大型数据的东西,单单处理器够用是不行的,显卡,内存等其它配件也要跟的上。

算完了数字,再说说加减乘除符号或是英文字母是怎么放入内存的呢?
还是转为二进制;
我都说了,计算机只认二进制,你们怎么刚说完就忘了?然道被我刚才那个32位电脑地址搞懵了是把?
哈哈哈。那个先不管,32位电脑,64位电脑你其实不能把它看成位,那个你不用记,你只要记住前面数字怎么放入位就可以,我们现在说的这个字符和字母其实是通过一本老外发明的
翻译本标准
翻译本 编译器 ——傻傻分不清楚?
编译器呢,就是我们前面已经说了。
那翻译本呢,有很多,我们现在说的这个符号和字母的翻译本叫:
ascll码 也叫 阿斯克码值(或阿斯克码表)

这个也是一种标准,一种已经在库函数就做好了的标准,它就在编译器里。
你在编译器就可以设置,不用再引入代码里。编译器会根据这个翻译本翻译好数值后,在经过stdio.h的标准进入内存。
然后文字呢?
就说说汉字怎么存入内存呢?
这下子都知道了,还是通过二进制存入内存里。
但文字和字母还有字符不一样呀。
怎么转为二进制呢?
有的人又知道了,还是翻译本。
老外又作了一本国际通用的万国翻译本,也叫万国本,就我们经常看到什么office办公软件或是其他什么软件经常看到左下角或是右下角有个
UTF-8
这个就是万国本,所有国家通用,就是将某国的文字转换为十六进制(十六进制更可读,更紧凑,更效率)在转为二进制存入内存。

别急,有的人应该也经常看看到:
GBK或是GB2312
这个就是我们国人自己做的翻译本。哪有可能全是老外占了呢,是吧。

说到这,你们要理解了,对编程,已经会了50%了。

未来的编程方面,我们国家已经开始超越国外的了,现在国外的月亮已经不圆了,因为那里的月亮满是傲慢。
现在华为出了个:
仓颉(cang jie)编程
这个听说比C语言或是其它语言更便捷,还有丰富的库函标准用,直接编译,不用再代入什么引用标准。半逻辑打代码运行,比自己瞎逻辑添加还强。
而且国家有些部门也在研究自己的系统,慢慢脱离linux的核心控制。
未来真的可期!!!









发表回复